
A utility-scale solar plant is a real-time control system that happens to be sold as a real estate asset. Inverters need setpoints. Trackers need angle commands. Curtailment signals from the grid operator arrive on the minute and must be applied on the minute. Alarms have to reach the operator before the fault propagates. Energy meters have to be polled on the cadence the BRP settlement timetable demands. Every one of these is a real-time obligation — and every one of them is, in a pure cloud-only SCADA architecture, dependent on a public-internet round trip going perfectly every time, day and night, in every weather, through every ISP outage, behind every firewall change, forever.
That assumption breaks. It breaks slowly during normal operation, and it breaks catastrophically when something goes wrong upstream. The question is not whether a plant's WAN link will fail this year — it will — but what happens during the failure, and what state the plant comes back to when the link returns.
This article is about the SCADA architecture decision that determines the answer. We'll work through the four pain points that the pure cloud-only model produces at utility scale, then describe the edge-first pattern that solves them — what it does, how the capability allocation between edge and cloud actually works, and what to demand from a SCADA vendor when you sit down to procure one.
- Cloud-only SCADA assumes a perfect public-internet link, every minute, forever — an assumption that breaks predictably and expensively at utility scale.
- Four pain points recur: blind operation during WAN outages, accumulated round-trip latency on control loops, security boundaries collapsed onto the public internet, and vendor lock-in with no rollback path.
- The edge-first pattern keeps control, polling, alarming, and settlement-grade data capture local; the cloud layer becomes a sync target and an analytics surface, not a critical-path dependency.
- Capability allocation matters more than where things 'run' — decide deliberately what survives a WAN outage and what does not, and write the boundary down.
- The edge-first pattern is a procurement checklist item, not an implementation detail — ask the SCADA vendor explicitly which functions degrade and which fail when the cloud is unreachable.
Pain 1 · WAN Outages Mean Blind Operation
Every plant in the world will lose its WAN link at some point. ISP transit failures, fibre cuts during road works, BGP routing incidents, regional cell-network outages, expired SIM cards on the cellular failover, customs holding the replacement router at the border, an excavator on the access road, a thunderstorm on the rooftop antenna. The frequency is low per individual cause. The aggregate frequency over a 25-year asset lifetime is high. Several days of cumulative WAN downtime per plant per year is not a worst case — it is a normal case.
In a cloud-only SCADA architecture, every one of those minutes is a minute the operator is blind. The dashboard stops updating. Alarms stop being generated against fresh telemetry — there is no fresh telemetry. Curtailment commands queued in the cloud have nowhere to land. The historian that the lender's IEC 61724-1 performance ratio calculation depends on is missing rows.
The consequences are concrete:
- Faults propagate undetected. A string-level fault that would normally trigger an alarm in seconds sits silent. By the time the link returns, the inverter has either tripped (best case — recoverable) or continued operating with the fault, accumulating revenue loss the lender expects you to explain in the next quarterly PR meeting (worst case — argument).
- Curtailment commands miss the window. The grid operator does not care whether your dashboard was online when they sent the setpoint. The TSO setpoint is a contractual obligation with a response-time SLA measured in seconds-to-minutes. Missing it is a penalty event regardless of whose link was down.
- Settlement data has holes. The BRP and the meter operator both need a continuous, time-aligned record of plant export for imbalance settlement and quarterly reconciliation. Holes in the historian mean estimated readings, mean disputed invoices, mean a meeting with the settlement counterparty you would have preferred to avoid.
- The operator cannot intervene manually. When something goes visibly wrong from the field — smoke, a fire alarm, a transformer humming the wrong way — the natural response is to log in and see what the SCADA is reporting. If the SCADA was the cloud and the cloud is what is gone, the operator is back to a torch and a pair of binoculars.
The cloud-only counter-argument is "but our cloud has 99.99% uptime." That argument confuses the cloud's uptime with the connection between the plant and the cloud's uptime. The two are different numbers. The plant link is the variable that matters, and at a remote utility-scale solar site that variable is structurally worse than the datacentre's.
Pain 2 · Round-Trip Latency Accumulates on Control Loops
Even when the WAN is working, a cloud-only SCADA pays for every control decision in round-trip latency. The packet path for a single inverter setpoint write from a pure-cloud SCADA looks like this:
Cloud UI → cloud API → cloud queue → cloud egress → plant gateway →
plant LAN → inverter → ACK → plant LAN → plant gateway → cloud ingress →
cloud event log → cloud UI
Each arrow is a real network hop with a real distribution of latencies and a real probability of dropped packets. The mean total time for the round trip is rarely the problem — the tail of the distribution is. P99 latencies on intercontinental cloud paths regularly cross the second mark; P99.9 latencies cross several seconds; the long tail goes wherever TCP retransmits or BGP route changes take it.
For a slow loop — say, a daily inverter parameter change — none of this matters. For real-time loops, it does:
- Curtailment setpoint propagation. The TSO sends a curtailment command with a fixed response window. Every cloud round trip the platform inserts between the TSO ingestion point and the inverter eats into that budget. A cloud-only model that uses three cloud round trips to validate, queue, and dispatch the command has half the response margin of a local model that dispatches directly.
- Tracker control loops. Single-axis trackers in a fast-changing diffuse-fraction regime want sub-second feedback. A cloud-mediated tracker controller cannot make sub-second decisions because the cloud round trip itself isn't sub-second on the tail.
- Fault response automation. "If string current drops more than X% relative to siblings for more than Y seconds, isolate the string." A local controller can act on this rule in tens of milliseconds. A cloud-mediated controller cannot — it has to pull the live data through the same RTT pipeline before it can decide.
- Coordinated reactive-power dispatch. PCS and inverter reactive-power coordination during a grid-code event is by definition real-time. It cannot wait for a cloud round trip, and a SCADA architecture that pretends it can is a SCADA architecture that will be silently bypassed by the inverter's local controller — which means the cloud SCADA's reactive-power dashboard is showing a fiction.
The clean version of this argument: any control function whose response-time SLA is shorter than the WAN P99 round trip must run locally. Anything else is dashboard, not control.
Pain 3 · Security Exposure of a Pure-Cloud Boundary
The cloud-only model concentrates risk on a single attack surface: the link between the plant and the public internet. Every Modbus register read, every alarm acknowledgement, every setpoint write traverses that surface. Hardening it is non-trivial. Most cloud-only deployments do one of two things, both of which carry significant compromises:
-
Expose plant gateways through inbound firewall holes. This puts industrial protocol endpoints — historically designed for trusted networks, not the public internet — directly reachable from outside the plant. Modbus TCP has no native authentication or encryption. Even when wrapped in TLS at the gateway, every newly published CVE in the gateway firmware is now an internet-facing CVE.
-
Tunnel everything outbound via a vendor-managed connection. This shifts the risk surface from the plant boundary to the vendor's cloud infrastructure. The plant becomes only as secure as the vendor's tunnelling layer. Recent industrial-IoT incidents involving compromised vendor cloud relays have demonstrated that this concentration is itself a vulnerability — when the vendor is breached, every plant connected through them is breached.
The edge-first alternative — keeping the industrial protocols on the plant LAN and exposing only a small, well-defined, authenticated cloud-sync channel — reduces the attack surface materially. The plant's Modbus traffic never traverses the public internet. The cloud-sync channel can be a signed outbound-only stream of telemetry summaries and command acknowledgements with no inbound surface for an attacker to probe.
This is also where regulatory pressure is heading. The EU NIS2 directive, the IEC 62443 industrial-cybersecurity series, and national cybersecurity authorities in jurisdictions across Europe are increasingly explicit about the expectation that industrial control systems run on segmented networks with defined, auditable boundaries. A SCADA architecture that puts the inverter on the public internet via a gateway port-forward is going to age badly under the next round of audits.
Pain 4 · Vendor Lock-in With No Rollback Path
The fourth pain point is the one that does not hurt on day one and hurts the most over the 25-year asset life. A pure cloud-only SCADA is, by construction, a multi-tenant SaaS product owned and operated by a single vendor. Three things follow.
The data is in their database, in their schema, in their region. Extracting it is at best a slow export job and at worst an SLA negotiation. The lender's PR reconciliation, the buyer's due diligence, the regulatory audit — all of these want continuous historical telemetry. The vendor's commercial interest is for that data to be sticky.
The control plane is their UI. Operator training, runbook documentation, alarm-management workflows, integration with the maintenance ticketing system — all of these accumulate against the specific UI and API conventions of one vendor. Switching is expensive in retraining and runbook rewriting even when it is technically possible.
There is no rollback. A cloud-only SCADA upgrade is performed by the vendor on the vendor's schedule. The plant does not get a choice. When the vendor pushes a UI change that breaks an alarm workflow, or deprecates an API endpoint the lender's analytics rely on, the only response is a support ticket and a wait. There is no equivalent of "stay on the prior firmware until the next maintenance window."
The edge-first pattern does not eliminate the vendor relationship, but it changes the leverage. The on-plant data store is a real database the asset owner can query directly, back up directly, and migrate from directly. The cloud layer is a sync target, not the source of truth. Replacing the cloud-side analytics vendor is a project; replacing a pure-cloud SCADA vendor is a forklift.
The Edge-First Pattern, Described
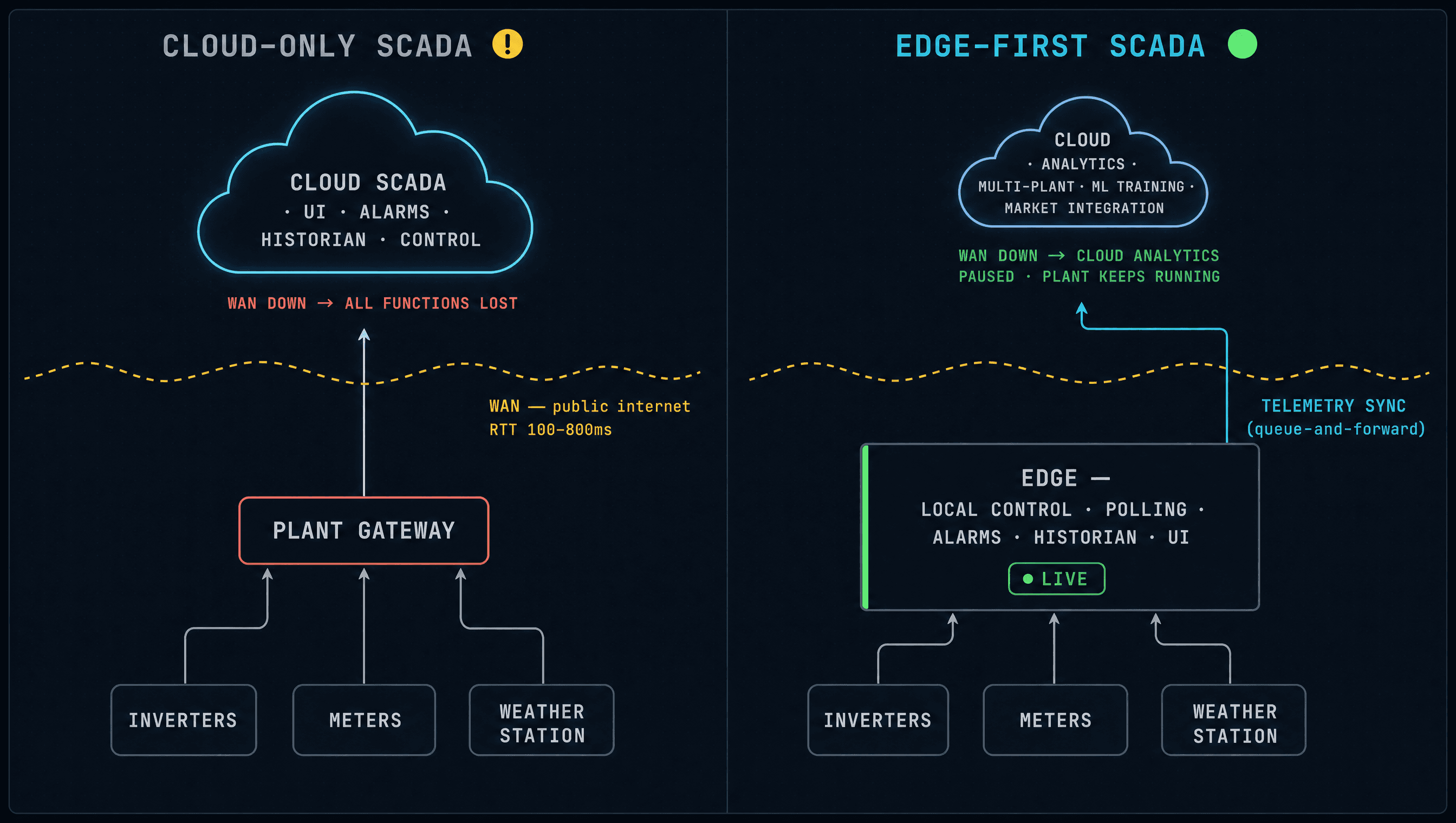
The edge-first SCADA pattern is not a hardware choice — it is an architectural commitment to where state lives, where decisions are made, and what happens to the plant when the cloud is unreachable. It is independent of the specific compute, the specific protocols, and the specific cloud provider. The commitments are these.
1. Real-time control and polling live at the plant
Every function with a sub-minute response requirement runs on local compute connected to the plant LAN. That includes Modbus polling of inverters, string monitors, weather stations, energy meters, and the local PCS. It includes alarm evaluation against fresh telemetry. It includes the closed-loop curtailment dispatch, the tracker control feedback, and any fault-response automation. Everything in this set continues to operate when the WAN is gone.
2. The historian is local-first, cloud-synced
Settlement-grade telemetry — the meter readings, the inverter-level energy registers, the alarm log, the operator action log — is written to a local time-series store on the plant. Writes are durable on the local disk first. The cloud sync is a streaming pipeline that runs continuously when the WAN is up and queues telemetry on the local disk when the WAN is down. When the link returns, the queue drains. The downstream cloud-side historian backfills without holes.
This is the architectural property that lets the IEC 61724-1 PR reconciliation, the BRP settlement, and the lender's reporting all continue to be correct after a multi-hour WAN outage. The asset's record of what actually happened was never dependent on the link being up.
3. The operator UI works on both sides
The on-plant operator UI is served from the local compute and is reachable on the plant LAN regardless of WAN status. The cloud operator UI is reachable from anywhere with internet access and reflects the synced state. The two views are consistent during normal operation; during a WAN outage the on-plant view is authoritative and the cloud view shows its last-known timestamp. There is no scenario in which both views are simultaneously unreachable.
4. Control commands have a defined authority hierarchy
When the cloud sends a setpoint and the link is up, the command flows to the edge controller and out to the device. When the cloud is unreachable, the local autonomous policies remain in force — curtailment is held at the last-known setpoint, tracker control runs from the local optimisation, fault-response automation continues to act on local data. When the link returns, the cloud reconciles against the local state rather than overwriting it.
5. The cloud handles what only the cloud can do
Multi-plant portfolio rollups. Cross-site benchmarking. Long-horizon analytics. ML model training against the aggregated historical record. Forecast ingestion from external weather providers. Market-data integration. None of these need to be in the real-time path. None of them are degraded by a 100ms or 10s cloud round trip — they are batch or near-real-time by nature. The cloud layer earns its keep by doing the things that benefit from aggregation and centralised compute, not by being the choke point for every Modbus read.
Capability Allocation: What Lives Where
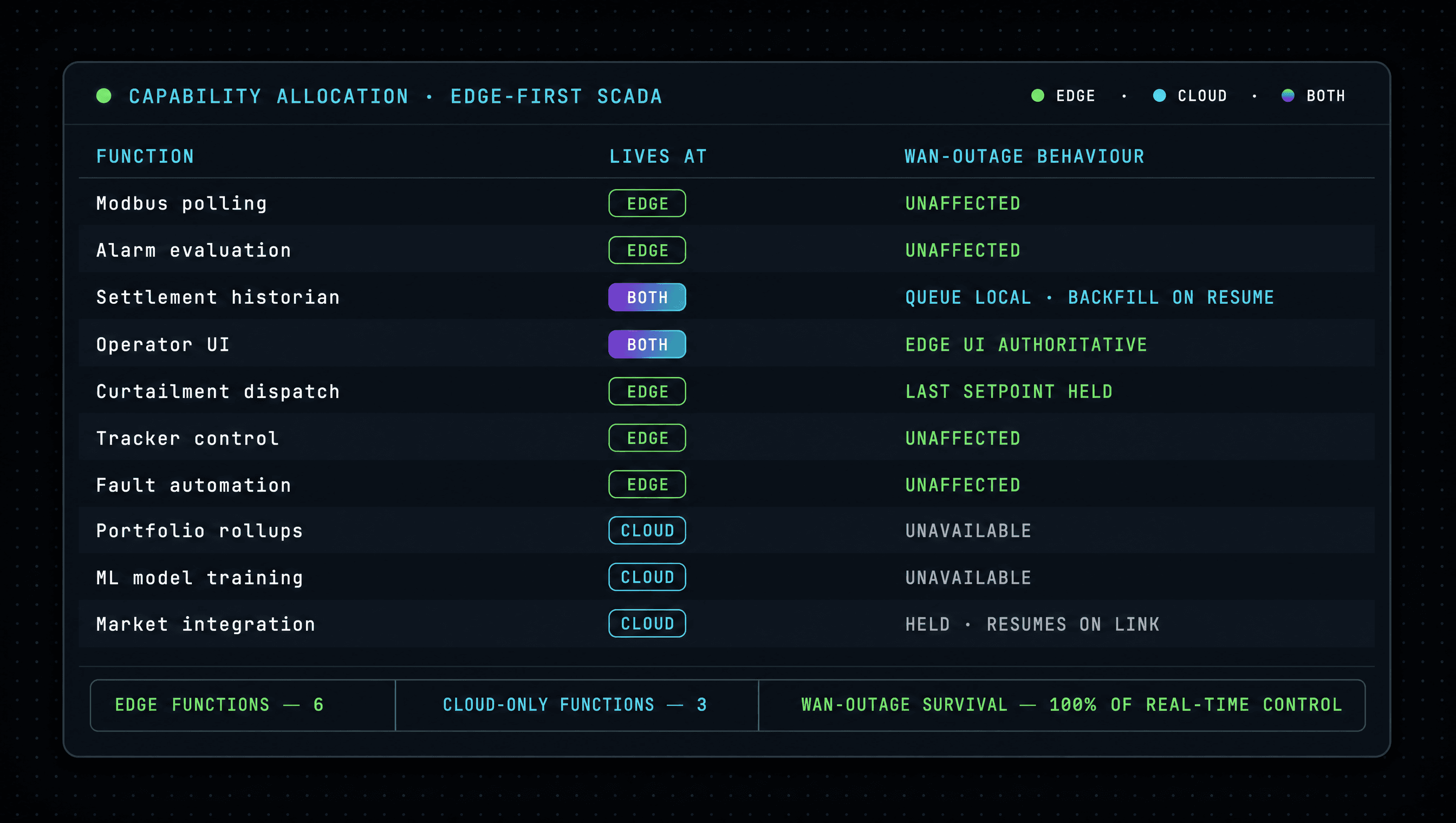
The single most useful artefact in an edge-first SCADA design review is the capability allocation matrix. It says, function by function, which side of the boundary the function runs on — and equally importantly, what its degraded-mode behaviour is when the cloud is unreachable.
| Function | Lives at | Degraded mode if cloud unreachable |
|---|---|---|
| Modbus polling (inverters, meters, weather) | Edge | Unaffected |
| Alarm evaluation against live telemetry | Edge | Unaffected |
| Operator UI (read & basic acknowledge) | Edge + Cloud | Edge UI authoritative; cloud UI shows last-sync timestamp |
| Curtailment setpoint dispatch (TSO → inverter) | Edge | Last-known setpoint held; backlog reconciled on resume |
| Tracker control loop | Edge | Unaffected |
| Fault-response automation | Edge | Unaffected |
| Settlement-grade historian | Edge + Cloud sync | Edge writes durably; cloud backfills on resume |
| Operator action audit log | Edge + Cloud sync | Edge logs locally; cloud backfills on resume |
| Multi-plant portfolio dashboard | Cloud | Unavailable until link returns |
| Cross-site benchmarking & analytics | Cloud | Unavailable until link returns |
| ML model training (forecasting, anomaly) | Cloud | Unavailable until link returns |
| External forecast ingestion | Cloud | Last-known forecast used at edge until refresh |
| Market-data integration & bid construction | Cloud | Held; resumes on link return |
| Long-horizon reporting & PR reconciliation | Cloud | Generated from synced historian once link returns |
The point of the matrix is not that every row is necessarily correct for every plant — it is that the discussion happens explicitly. A SCADA vendor that cannot fill out the right-hand column on demand does not know its own architecture well enough to be deployed at utility scale.
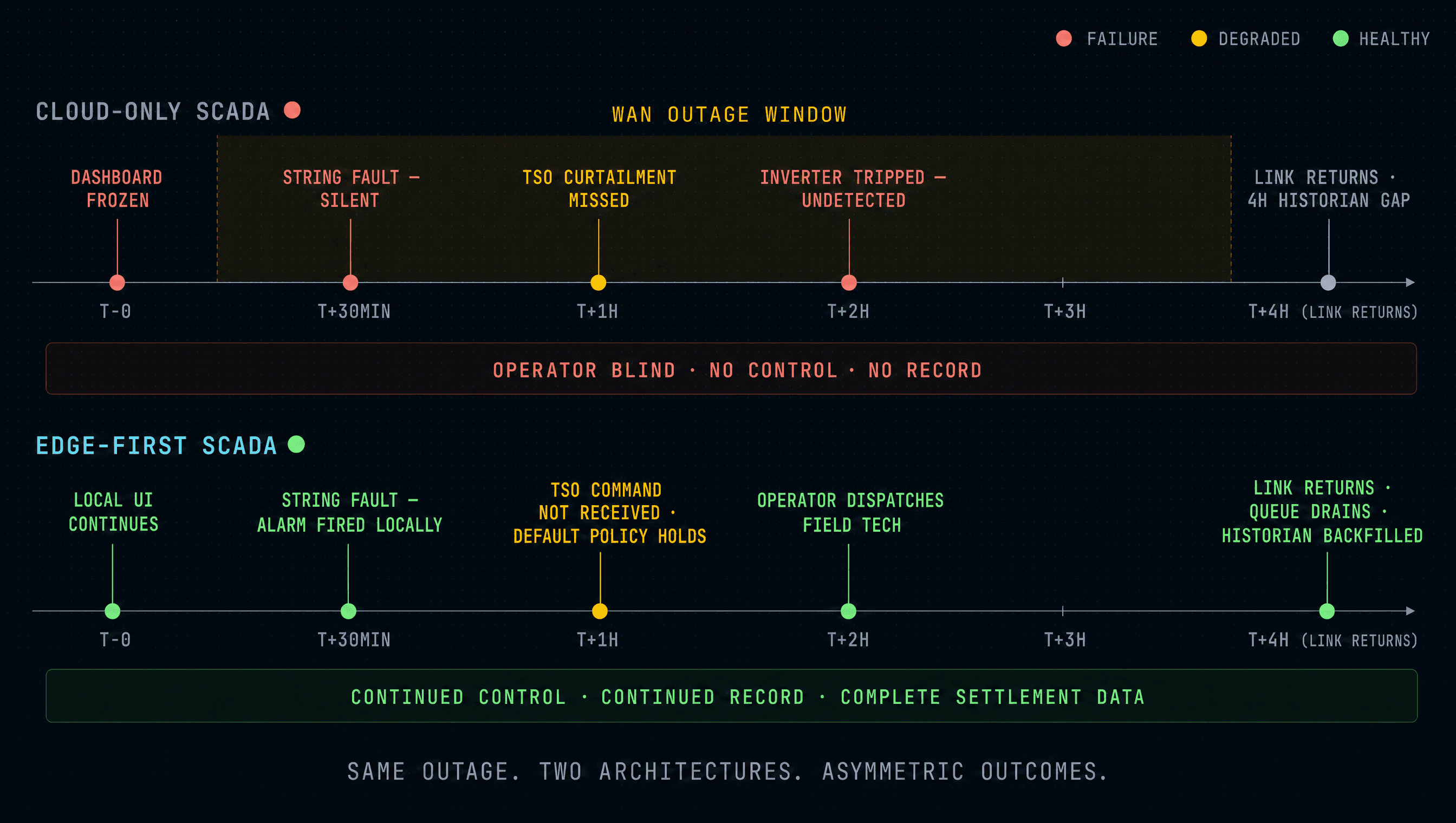
A Four-Hour Outage, Two Architectures
Consider a single, common scenario: a four-hour mid-day WAN outage at a 20 MW plant during a summer week. Convective weather, a curtailment event from the TSO, a string fault that develops during the outage window.
The cloud-only plant. The dashboard is frozen on the operator's screen and on the asset manager's screen and on the trading desk's screen for four hours. The TSO curtailment command arrives at the cloud, queues, and never reaches the inverter — when the link returns and the queue drains, the inverter receives a setpoint that was relevant four hours ago and may now be wrong. The string fault sits silent because no fresh telemetry is reaching the cloud-side alarm engine; the inverter trips itself an hour into the event and continues being tripped until someone notices. The historian has a four-hour hole; the BRP settlement reconciliation a week later requires manual estimation and a follow-up call.
The edge-first plant. The operator's on-plant UI continues to function on the plant LAN. The TSO curtailment command does not reach the plant during the outage — that is a real loss — but the local controller is configured with default-curtail-on-loss-of-grid-comms policy, so the plant operates at the conservative setpoint until the link returns and the live setpoint resumes. The string fault is caught by the local alarm engine within seconds of the fault signature appearing in sibling-current data; the on-plant operator UI shows the alarm and the operator dispatches the field tech without waiting for the cloud to come back. The local historian writes every reading to local disk; when the link returns, the four-hour backlog streams up to the cloud historian in minutes and the BRP settlement record is complete and continuous.
The asymmetry is not subtle. The cloud-only plant accumulates losses through the outage and operational debt for weeks afterwards. The edge-first plant takes a smaller, bounded loss during the outage and resumes normal operation without explanation calls or settlement disputes.
Procurement Checklist: What to Demand From a SCADA Vendor
When evaluating a SCADA platform for utility-scale solar, the architecture conversation should produce concrete, verifiable answers to the following questions. Vendors that struggle with any of them are telling you something important.
- Which functions continue to operate when the WAN link is down? Ask for the capability allocation matrix. Ask in writing. A vendor that cannot produce one is shipping an unspecified product.
- How long can the platform operate disconnected from the cloud before any function degrades? Hours, days, weeks. A serious edge-first product runs autonomously for as long as the local storage holds out.
- Where is the settlement-grade historian stored, and what is the durability guarantee on the on-plant disk? "In the cloud" is the wrong answer.
- What is the cloud-sync recovery behaviour after an outage? Specifically: does the cloud historian backfill, does the operator log backfill, does the alarm history backfill — and what is the maximum supported queue depth before the local store stops accepting writes?
- What ports and protocols are exposed to the public internet from the plant? Bonus: ask about NIS2 and IEC 62443 alignment. The answer reveals the vendor's seriousness about industrial cybersecurity.
- How does the platform behave when the cloud sends a stale command after a long outage? Acceptance-without-validation is dangerous; the platform should reconcile the local state with the cloud's commanded state, not blindly apply the latter.
- What is the on-plant operator UI? Some vendors do not have one. That is a red flag.
- What is the data-portability story? Can you export the entire historian, the entire alarm log, the entire operator audit log into a standard format on demand?
- What is the upgrade and rollback model? A platform that pushes upgrades to the edge automatically and cannot roll back is a platform that will eventually push a bad upgrade on a Sunday.
- What does the platform do during a partial WAN outage — high latency, packet loss, partial connectivity? The interesting failure modes are the ambiguous ones, not the clean ones.
A vendor whose answers are vague, conditional, or contingent on "the roadmap" is selling you a cloud-only product with edge-first marketing. Edge-first is an architectural commitment, not a feature flag.
Frequently Asked Questions
Conclusion
The SCADA architecture decision is a 25-year decision. The cloud-only model is convincing in a demo and convincing for the first calm year of operation. It stops being convincing the first time the WAN link is down for an afternoon during a curtailment event, or the first time the lender's quarterly PR meeting opens with "why is there a four-hour gap in the historian on March 14th?" By then the architecture is hardwired into the operator's runbooks and the asset owner's procurement and the financing covenants, and the cost of fixing it is no longer a SCADA conversation — it is a forklift.
The edge-first pattern is not exotic. It is what every other category of mission-critical industrial control system has converged on over the last forty years, and it is the answer the solar industry will eventually converge on too. The plants and portfolios that move first capture the operational reliability, the security posture, the data ownership, and the procurement leverage that the latecomers will spend a decade trying to retrofit.
DYNVOLT is an edge-first SCADA platform built specifically for utility-scale solar. Local compute runs polling, alarming, control, and settlement-grade data capture; the cloud layer is the portfolio-wide analytics, forecasting, and market-routing surface. See the architecture overview, the SCADA module, or request a 14-day pilot to test the edge-first behaviour against the failure modes that matter to your plant.


